AWS Certified Solutions Architect - Associate (SAA-C03)

- 1015 exam-style questions
- Detailed explanations and references
- Simulation and custom modes
- Custom exam settings to drill down into specific topics
- 180-day access period
- Pass or money back guarantee
What is in the package
The tone and tenor of the questions mimic the actual exam. Along with the detailed description and exam tips provided within the explanations, we have extensively referenced AWS documentation to get you up to speed on all domain areas tested for the SAA-C03 exam.
Complete SAA-C03 domains coverage
CertVista SAA-C03 is organized into four domains that closely relate to the topics necessary to cover the exam.
1. Design Secure Architectures
Designing secure applications and architectures is covered in domain one. This domain reviews designing secure access to AWS resources, application tiers, and data security options.
2. Design Resilient Architectures
Domain two covers designing resilient architectures. This domain focuses on multi-tier solutions, highly available and fault-tolerant architectures, AWS services used as decoupling mechanisms, and appropriate resilient storage options.
3. Design High-Performing Architectures
Domain three, which is about designing high-performing architectures, will guide you through identifying elastic and scalable compute and storage solutions, and selecting high-performing network and database solutions.
4. Design Cost-Optimized Architectures
The fourth and final domain focuses on designing cost-optimized architectures. This is where you'll look at identifying cost-effective storage, compute, database solutions, and designing cost-optimized network architectures.
CertVista's Solutions Architect - Associate question bank features hundreds of exam-style questions meticulously designed to mirror the actual SAA-C03 certification exam. Practice with a variety of question formats, including multiple-choice, multiple-response, and complex scenario-based questions focused on real-world AWS architectural challenges. Our exam engine familiarizes you with the testing interface and conditions, ensuring you can confidently approach your certification day.
Every CertVista SAA-C03 question includes comprehensive explanations and direct references. These explanations break down the core AWS architectural principles, link to relevant official AWS documentation, and clarify common design and implementation misconceptions. You'll understand why the correct answer best meets the architectural requirements posed in the question and why alternative solutions fall short.
CertVista provides two powerful study modes tailored for SAA-C03 preparation. Use Custom Mode for targeted practice on specific AWS architectural domains, perfect for reinforcing knowledge in areas like designing resilient architectures, high-performing architectures, secure applications and architectures, or cost-optimized architectures. Switch to Simulation Mode to experience the complete 130-minute exam environment with realistic time constraints and question weighting, effectively building your test-taking endurance and confidence.
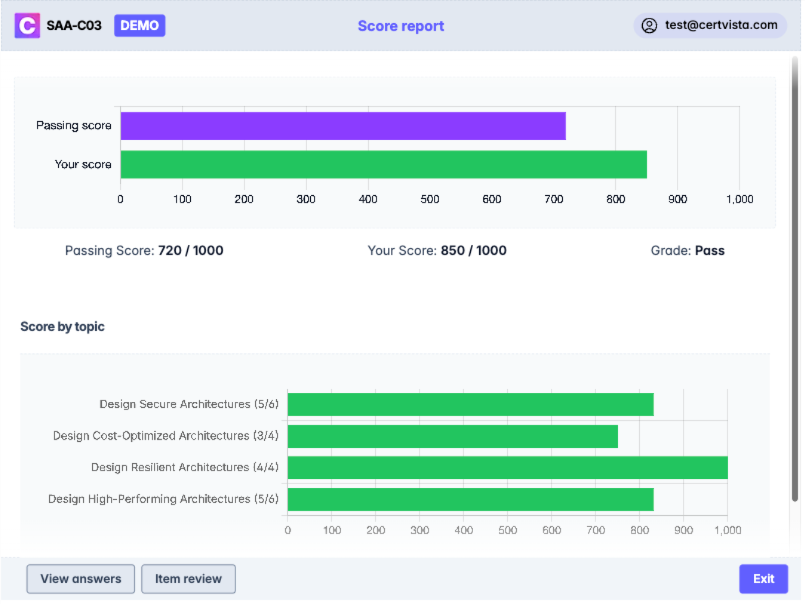
Leverage the CertVista analytics dashboard for insights into your AWS Certified Solutions Architect - Associate preparation journey. Monitor your performance across all key exam domains – Design Resilient Architectures, Design High-Performing Architectures, Design Secure Applications and Architectures, and Design Cost-Optimized Architectures. Pinpoint knowledge gaps, refine your study plan for maximum efficiency, and gain the confidence to know exactly when you're prepared to pass the SAA-C03 exam.
What's in the SAA-C03 exam
The SAA-C03 certification exam is intended for individuals with a solutions architect role and one or more years of experience designing highly available, cost-efficient, fault-tolerant, and scalable distributed systems. The Certified Solution Architect - Associate certification validates your ability to design and implement systems on AWS, highlighting your capacity to incorporate resiliency, high performance, security, and cost optimization.
During the exam, you'll be asked to complete tasks such as evaluating the design and implementation of multi-tiered and highly available architectures, using scaling for compute and storage solutions, identifying cost-effective solutions, and more. The AWS Certified Solutions Architect Associate certification validates you have the knowledge, depth, and experience to do the following.
- Design solutions incorporating AWS services to meet current business requirements and projected needs.
- Design architectures that are secure, resilient, high-performing, and cost-optimized
- Review existing solutions and determine improvements.
What are the questions like on the exam?
There are two types of questions on the exam: multiple choice, which has one correct response and three incorrect responses, or distractors, or multiple responses, which has two or more correct responses out of five or more response options.
During the exam, you will be asked to choose the best answer for scenarios to complete tasks to design and implement systems on AWS.
This highlights your capacity to incorporate resiliency, high performance, security, and cost optimization. The questions' overall length, complexity, and difficulty tend to be longer and more complicated than what you might expect from an associate-level certification exam. Most questions involve lengthy scenarios, usually several sentences to a couple of paragraphs.
Most of the answer choices will be several sentences long as well. So, take your time as you're reading through these longer questions, and be sure to process every word you read in detail. Be on the lookout for repeated sentences across all of the possible answers with just a word or two change.
Those one or two words can make all the difference when determining which answer is correct and which might be a distractor. Always do your best to eliminate these distractors as early as possible so you can focus more on the plausible answers and select the best answer to each question.
Sample SAA-C03 questions
Get a taste of the AWS Certified Solutions Architect - Associate exam with our carefully curated sample questions below. These questions mirror the actual SAA-C03 exam's style, complexity, and subject matter, giving you a realistic preview of what to expect. Each question comes with comprehensive explanations, relevant documentation references, and valuable test-taking strategies from our expert instructors.
While these sample questions provide excellent study material, we encourage you to try our free demo for the complete SAA-C03 exam preparation experience. The demo features our state-of-the-art test engine that simulates the real exam environment, helping you build confidence and familiarity with the exam format. You'll experience timed testing, question marking, and review capabilities – just like the actual certification exam.
A company has created an image analysis application in which users can upload photos and add photo frames to their images. The users upload images and metadata to indicate which photo frames they want to add to their images. The application uses a single Amazon EC2 instance and Amazon DynamoDB to store the metadata.
The application is becoming more popular, and the number of users is increasing. The company expects the number of concurrent users to vary significantly depending on the time of day and day of week. The company must ensure that the application can scale to meet the needs of the growing user base.
Which solution meats these requirements?
Use AWS Lambda to process the photos. Store the photos and metadata in DynamoDB.
Increase the number of EC2 instances to three. Use Provisioned IOPS SSD (io2) Amazon Elastic Block Store (Amazon EBS) volumes to store the photos and metadata.
Use Amazon Kinesis Data Firehose to process the photos and to store the photos and metadata.
Use AWS Lambda to process the photos. Store the photos in Amazon S3. Retain DynamoDB to store the metadata.
Using AWS Lambda for processing provides automatic scaling, which allows the application to handle varying concurrency without having to manually provision or manage servers. Storing the photos in Amazon S3 is cost-effective and ensures virtually unlimited scalability. Retaining Amazon DynamoDB for the metadata is also ideal because DynamoDB offers consistent performance at any scale, especially when properly using features like auto scaling.
A solution that stores both data and images in DynamoDB alone can become costly and is not typically the recommended practice for storing large objects like photos. Simply increasing the number of Amazon EC2 instances and using Provisioned IOPS volumes can help with performance but does not natively handle highly variable traffic without additional services or elasticity configurations. Using services specifically for streaming and data ingestion is more aligned with continuous data ingestion scenarios, which does not match the real-time image processing requirements as effectively as a serverless approach with Lambda and S3.
In a real-world scenario, this strategy provides a scalable architecture for image processing. For instance, the Lambda function can be triggered each time an object is put into an S3 bucket. The function can then apply the desired transformations or frames to the uploaded photo. DynamoDB remains well-suited for storing metadata such as user preferences, timestamps, and relevant attributes about the photo frames.
For test takers, remember that AWS Lambda and Amazon S3 are a common pairing for serverless file processing tasks that can seamlessly scale up and down without upfront server provisioning. DynamoDB is appropriate for storing JSON-like metadata with low-latency reads and writes. When you see a question about unpredictable or spiky traffic, serverless architectures can quickly adapt to demand while preventing over-provisioning.
A company is building a web-based application running on Amazon EC2 instances in multiple Availability Zones. The web application will provide access to a repository of text documents totaling about 900 TB in size. The company anticipates that the web application will experience periods of high demand. A solutions architect must ensure that the storage component for the text documents can scale to meet the demand of the application at all times. The company is concerned about the overall cost of the solution. Which storage solution meets these requirements MOST cost-effectively?
Amazon Elastic Block Store (Amazon EBS)
Amazon OpenSearch Service (Amazon Elasticsearch Service)
Amazon S3
Amazon Elastic File System (Amazon EFS)
In this scenario, a web-based application must read and store a large repository of text documents—totaling 900 TB. Amazon Simple Storage Service (Amazon S3) provides virtually unlimited scalability at a more cost-effective rate compared to alternatives, such as Amazon EBS or Amazon EFS. Employing an object-based storage solution is ideal for this workload because it can handle high throughput and deliver the necessary durability and availability. By contrast, a service like Amazon OpenSearch Service (Amazon Elasticsearch Service) is well-suited for search and analytics but would be prohibitively expensive to store all 900 TB of data long-term.
Using Amazon S3 also offers flexible storage classes (e.g., S3 Standard, S3 Intelligent-Tiering, or S3 Glacier) that can further optimize storage costs, especially for data that is accessed infrequently. This combination of scalability and tiered pricing makes Amazon S3 the most cost-effective choice for hosting and delivering large volumes of static data.
Example
A common approach is to serve static files—such as large text documents—from an S3 bucket using presigned URLs or by fronting S3 with Amazon CloudFront as a content delivery network to reduce latency and offload traffic from origin servers. The combination of S3, CloudFront, and EC2 ensures that the solution can auto scale when needed while minimizing overall costs.
Review various Amazon S3 storage classes and ensure you understand how storage class transitions can help balance performance requirements and budget constraints.
A global company hosts its web application on Amazon EC2 instances behind an Application Load Balancer (ALB). The web application has static data and dynamic data. The company stores its static data in an Amazon S3 bucket. The company wants to improve performance and reduce latency for the static data and dynamic data. The company is using its own domain name registered with Amazon Route 53.
What should a solutions architect do to meet these requirements?
Create an Amazon CloudFront distribution that has the ALB as an origin. Create an AWS Global Accelerator standard accelerator that has the S3 bucket as an endpoint Configure Route 53 to route traffic to the CloudFront distribution.
Create an Amazon CloudFront distribution that has the S3 bucket as an origin. Create an AWS Global Accelerator standard accelerator that has the ALB and the CloudFront distribution as endpoints. Create a custom domain name that points to the accelerator DNS name. Use the custom domain name as an endpoint for the web application.
Create an Amazon CloudFront distribution that has the ALB as an origin. Create an AWS Global Accelerator standard accelerator that has the S3 bucket as an endpoint. Create two domain names. Point one domain name to the CloudFront DNS name for dynamic content. Point the other domain name to the accelerator DNS name for static content. Use the domain names as endpoints for the web application.
Create an Amazon CloudFront distribution that has the S3 bucket and the ALB as origins. Configure Route 53 to route traffic to the CloudFront distribution.
Serving both static and dynamic content through a single Amazon CloudFront distribution—where static content is sourced from Amazon S3 and dynamic content from the Application Load Balancer (ALB)—is a best practice for optimizing performance and reducing latency. CloudFront’s global network of edge locations helps cache and accelerate the delivery of both types of content to end users. By configuring multiple origins (S3 for static assets and ALB for dynamic requests) within the same CloudFront distribution, you can use path-based routing to cache static assets while allowing pass-through of dynamic requests to the ALB. Amazon Route 53 can then provide DNS resolution, typically via an alias record, that points to the CloudFront distribution. This approach simplifies your architecture and reduces cost by eliminating the need to introduce AWS Global Accelerator for this scenario.
Using AWS Global Accelerator is valuable in specific use cases—such as non-HTTP/HTTPS traffic or multi-region active-active ALB deployments—but for a standard web application serving static and dynamic data over HTTP/HTTPS, a single CloudFront distribution is typically sufficient to provide edge caching, global reach, and lower latency. Creating multiple domain names or separate endpoints would overcomplicate the setup and does not offer significant benefits over CloudFront alone in this common web-serving pattern.
Example
Assume you have an S3 bucket named “my-app-static-content” and an ALB with a DNS name of “my-app-alb-123456789.us-east-1.elb.amazonaws.com.” You can configure CloudFront with an origin for the S3 bucket to handle requests for paths like “/static/” and another origin for the ALB to handle “/api/” or “/dynamic/.” Then, you create a behavior in CloudFront that routes “/static/” to the S3 origin and another behavior that routes all other paths to the ALB origin. Finally, use Route 53 to create an alias record pointing to the CloudFront distribution, for example, “app.example.com → d1234abcdef.cloudfront.net.”
Look for key AWS services—CloudFront for caching and distribution, ALB for dynamic application traffic, S3 for static object storage, and Route 53 for DNS—when you see questions about global performance optimization. Understand how path-based routing in CloudFront lets you configure multiple origins in one distribution.
A company wants to run applications in containers in the AWS Cloud. These applications are stateless and can tolerate disruptions within the underlying infrastructure. The company needs a solution that minimizes cost and operational overhead.
What should a solutions architect do to meet these requirements?
Use Spot Instances in an Amazon EC2 Auto Scaling group to run the application containers.
Use On-Demand Instances in an Amazon EC2 Auto Scaling group to run the application containers.
Use Spot Instances in an Amazon Elastic Kubernetes Service (Amazon EKS) managed node group.
Use On-Demand Instances in an Amazon Elastic Kubernetes Service (Amazon EKS) managed node group.
The company seeks to run containerized applications in a manner that reduces both cost and operational overhead while still allowing the infrastructure to be occasionally disrupted. Because the applications are stateless, the workloads can be gracefully restarted when Spot Instances are reclaimed. A managed service for container orchestration, such as Amazon EKS, offloads many operational tasks like cluster control plane management and upgrades. Combining Amazon EKS with Spot Instances provides significant cost savings compared to On-Demand Instances, and the stateless nature of the application addresses the interruption risk associated with Spot Instances. This approach aligns well with cost optimization goals and allows the team to handle disruptions gracefully.
In practice, one might mix both Spot and On-Demand Instances in a managed node group to further optimize reliability and cost. The stateless design ensures service availability even when nodes scale in or out due to Spot interruptions. By offloading cluster management to AWS via a managed node group, the company avoids dealing with self-managed clusters, which can significantly reduce operational overhead.
Example
Consider a large-scale stateless web application that uses containers for microservices. By deploying these containers in Amazon EKS and configuring a managed node group to use Spot Instances, the team can benefit from Amazon EKS automatically managing node provisioning and updates. The deployment could reference a service like the Kubernetes Deployment controller to handle rolling updates, ensuring minimal downtime if a Spot Instance is reclaimed.
When an application can tolerate interruptions and needs to minimize cost, Spot Instances can be a great approach. If there is only a small subset of the application that must be continuously available, separate that component onto On-Demand Instances while still using Spot Instances for the rest to reduce overall costs.
A reporting team receives files each day in an Amazon S3 bucket. The reporting team manually reviews and copies the files from this initial S3 bucket to an analysis S3 bucket each day at the same time to use with Amazon QuickSight. Additional teams are starting to send more files in larger sizes to the initial S3 bucket.
The reporting team wants to move the files automatically analysis S3 bucket as the files enter the initial S3 bucket. The reporting team also wants to use AWS Lambda functions to run pattern-matching code on the copied data. In addition, the reporting team wants to send the data files to a pipeline in Amazon SageMaker Pipelines.
What should a solutions architect do to meet these requirements with the least operational overhead?
Configure S3 replication between the S3 buckets. Configure the analysis S3 bucket to send event notifications to Amazon EventBridge (Amazon CloudWatch Events). Configure an ObjectCreated rule in EventBridge (CloudWatch Events). Configure Lambda and SageMaker Pipelines as targets for the rule.
Create a Lambda function to copy the files to the analysis S3 bucket. Create an S3 event notification for the analysis S3 bucket. Configure Lambda and SageMaker Pipelines as destinations of the event notification. Configure s3:ObjectCreated:Put as the event type.
Configure S3 replication between the S3 buckets. Create an S3 event notification for the analysis S3 bucket. Configure Lambda and SageMaker Pipelines as destinations of the event notification. Configure s3:ObjectCreated:Put as the event type.
Create a Lambda function to copy the files to the analysis S3 bucket. Configure the analysis S3 bucket to send event notifications to Amazon EventBridge (Amazon CloudWatch Events). Configure an ObjectCreated rule in EventBridge (CloudWatch Events). Configure Lambda and SageMaker Pipelines as targets for the rule.
A minimal-overhead approach is to rely on Amazon S3’s built-in capabilities for automatically replicating objects to the analysis bucket, and then use Amazon EventBridge to fan out notifications to both an AWS Lambda function and Amazon SageMaker Pipelines. Configuring replication is simpler to manage and maintain than writing and running a custom AWS Lambda function for copying objects. Once objects are in the analysis S3 bucket, EventBridge can consume the “Object Created” events and forward them in parallel to Lambda and SageMaker Pipelines, removing the need for additional orchestration logic or separate triggers. This streamlines the entire data flow and avoids the complexity of custom code that polls or copies objects.
When the new files land in the analysis bucket via S3 replication, an EventBridge rule will detect the object creation event. The rule can invoke a Lambda function to perform the pattern-matching code, and can also trigger the workflow in SageMaker Pipelines using the appropriate API calls or a direct integration. This design uses managed services that handle scaling and high availability, ensuring consistent performance while requiring minimal operational overhead.
For example, consider a case where multiple teams are sending a growing volume of daily reports into the initial bucket. By configuring replication to the analysis bucket in the same or in a different Region, you ensure that new files arrive almost immediately in the bucket where your analytics processing occurs. Then EventBridge processes each object creation notification, triggering a Lambda function for real-time data validation or cleansing. In parallel, the same event can launch a SageMaker pipeline execution so that machine learning models can be retrained or produce new inferences.
Keep in mind that Amazon S3 supports sending event notifications to EventBridge, which is especially helpful when multiple downstream services (like multiple Lambda functions, SageMaker Pipelines, and more) need to be triggered in response to a single event. This avoids building complex custom code or chaining notifications, and it ensures operational simplicity.
A company runs a web-based portal that provides users with global breaking news, local alerts, and weather updates. The portal delivers each user a personalized view by using mixture of static and dynamic content. Content is served over HTTPS through an API server running on an Amazon EC2 instance behind an Application Load Balancer (ALB). The company wants the portal to provide this content to its users across the world as quickly as possible.
How should a solutions architect design the application to ensure the least amount of latency for all users?
Deploy the application stack in a single AWS Region. Use Amazon CloudFront to serve the static content. Serve the dynamic content directly from the ALB.
Deploy the application stack in a single AWS Region. Use Amazon CloudFront to serve all static and dynamic content by specifying the ALB as an origin.
Deploy the application stack in two AWS Regions. Use an Amazon Route 53 latency routing policy to serve all content from the ALB in the closest Region.
Deploy the application stack in two AWS Regions. Use an Amazon Route 53 geolocation routing policy to serve all content from the ALB in the closest Region.
Using Amazon CloudFront to serve both static and dynamic content is typically the most efficient solution for reducing global latency, because CloudFront has a wide network of edge locations that can quickly deliver content to end users. When CloudFront is configured to use an Application Load Balancer as its origin, clients benefit from optimized SSL/TLS termination at edge locations and persistent connections back to the origin. This ensures that not only the static assets but also the dynamic API responses are delivered as quickly as possible, no matter where the user is located.
By contrast, only caching static content in CloudFront and routing dynamic content directly from an origin can lead to slower responses for those dynamic requests. Deploying multiple Regions and relying solely on Route 53 latency or geolocation routing can be more complex and may require additional data synchronization or replication strategies. While multi-region designs can reduce latency, using CloudFront in front of a single-region ALB is often sufficient and simpler for many workloads.
Examples:
- If you have a news portal that needs to serve global users, CloudFront will cache static media at edge locations and accelerate API requests by reducing the round trip to a single origin.
- A personalized weather application that must retrieve real-time data benefits from CloudFront’s optimized path back to its ALB origin, ensuring fast and secure delivery of custom weather alerts.
Remember that CloudFront is not exclusively for static content. It can accelerate dynamic content by maintaining optimized connections to your origin. This approach can greatly reduce latency and network overhead for global user bases.
A company is launching an application on AWS. The application uses an Application Load Balancer (ALB) to direct traffic to at least two Amazon EC2 instances in a single target group. The instances are in an Auto Scaling group for each environment. The company requires a development environment and a production environment. The production environment will have periods of high traffic.
Which solution will configure the development environment most cost-effectively?
Change the ALB balancing algorithm to least outstanding requests.
Reduce the maximum number of EC2 instances in the development environment’s Auto Scaling group.
Reconfigure the target group in the development environment to have only one EC2 instance as a target.
Reduce the size of the EC2 instances in both environments.
Reconfiguring the target group in the development environment to have only one EC2 instance as a target is the most cost-effective solution among the choices. Development environments typically do not require the same level of high availability or performance as production environments. Reducing the number of running EC2 instances from a minimum of two to just one will directly cut the compute costs for the development environment significantly (potentially by 50% or more if more than two instances were running). This would involve adjusting the Auto Scaling group settings for the development environment to have a minimum, desired, and maximum capacity of one instance. While the general application design mentions 'at least two EC2 instances,' this is often a standard for production-like availability, which can be relaxed for a development environment to save costs.
Changing the ALB balancing algorithm to least outstanding requests is a performance optimization technique and does not directly reduce the number or size of EC2 instances, thus not impacting cost in the way intended.
Reducing the maximum number of EC2 instances in the development environment’s Auto Scaling group can prevent scaling up and save costs if the environment previously scaled beyond its typical needs. However, if the minimum and desired instance counts remain at two (to satisfy an 'at least two instances' policy), this option doesn't reduce the baseline running cost. Configuring for a single instance provides a more substantial baseline cost reduction for a typical development workload.
Reducing the size of the EC2 instances in both environments would reduce costs, but the question specifically asks about configuring the development environment. Furthermore, reducing instance sizes in the production environment might negatively impact its performance, especially since it's stated to have periods of high traffic. This option is less targeted and potentially detrimental to production.
For cost optimization in development environments, common strategies include reducing the number of running instances, using smaller instance types, and stopping resources when not in use. When 'at least two instances' is mentioned for availability, consider if this requirement can be relaxed for non-production environments to achieve significant cost savings.
- Amazon EC2 Auto Scaling cost optimization
- Best practices for AWS cost optimization
- Target groups for your Application Load Balancers - Elastic Load Balancing (An ALB can have a target group with a single target.)
A company is designing an application. The application uses an AWS Lambda function to receive information through Amazon API Gateway and to store the information in an Amazon Aurora PostgreSQL database.
During the proof-of-concept stage, the company has to increase the Lambda quotas significantly to handle the high volumes of data that the company needs to load into the database. A solutions architect must recommend a new design to improve scalability and minimize the configuration effort.
Which solution will meet these requirements?
Refactor the Lambda function code to Apache Tomcat code that runs on Amazon EC2 instances. Connect the database by using native Java Database Connectivity (JDBC) drivers.
Change the platform from Aurora to Amazon DynamoDProvision a DynamoDB Accelerator (DAX) cluster. Use the DAX client SDK to point the existing DynamoDB API calls at the DAX cluster.
Set up two Lambda functions. Configure one function to receive the information. Configure the other function to load the information into the database. Integrate the Lambda functions by using Amazon Simple Notification Service (Amazon SNS).
Set up two Lambda functions. Configure one function to receive the information. Configure the other function to load the information into the database. Integrate the Lambda functions by using an Amazon Simple Queue Service (Amazon SQS) queue.
A high-volume ingestion system can quickly overwhelm a Lambda function when it must handle data reception and database insertion simultaneously. By separating these responsibilities into two functions and introducing an Amazon SQS queue between them, the design becomes more scalable and resilient. One Lambda function can receive the incoming data through Amazon API Gateway and place it in the queue. The other Lambda function can then pull from the queue to load data into Amazon Aurora PostgreSQL asynchronously. This decoupled pattern prevents overloading the data-loading function and the database, because SQS will buffer incoming requests when volumes spike, protecting backend resources while still accepting incoming data.
Using a queue also eliminates the need to increase concurrency limits on a single function drastically. Instead, you can process messages at your own pace while effectively handling sudden bursts of traffic. This design minimizes configuration effort, because you are offloading the scaling complexity to a managed queue that handles incoming throughput automatically. Amazon SNS, while useful in some event-driven scenarios, would not offer the same level of control over concurrency and buffering, and rewriting the application to run on Amazon EC2 instances would add overhead. Similarly, changing the database engine to DynamoDB might require a fundamental rewrite or redesign of the data model, which is often impractical when an Aurora-compatible, relational database is needed.
Example:
Imagine a scenario where a web application receives user information in real time. The first function simply validates the incoming data and publishes each record to an SQS queue. A second function is configured with an SQS trigger to run automatically for each message (or batch of messages). This second function inserts records into the Aurora database. Even if hundreds of thousands of user records arrive within a short period, the queue naturally absorbs the spike. The Lambda function that processes the database inserts scales up to match the number of messages, but if it hits a limit or the database becomes a bottleneck, the messages remain in the queue, ensuring no data is lost.
Look for designs that reduce direct dependencies and allow each component to scale independently. AWS services like Amazon SQS provide a straightforward way to build highly scalable event-driven architectures, especially for high-throughput workloads.
A company’s security team requests that network traffic be captured in VPC Flow Logs. The logs will be frequently accessed for 90 days and then accessed intermittently.
What should a solutions architect do to meet these requirements when configuring the logs?
Use Amazon S3 as the target. Enable an S3 Lifecycle policy to transition the logs to S3 Standard-Infrequent Access (S3 Standard-IA) after 90 days.
Use Amazon Kinesis as the target. Configure the Kinesis stream to always retain the logs for 90 days.
Use Amazon CloudWatch as the target. Set the CloudWatch log group with an expiration of 90 days
Use AWS CloudTrail as the target. Configure CloudTrail to save to an Amazon S3 bucket, and enable S3 Intelligent-Tiering.
A suitable configuration is to deliver VPC Flow Logs to Amazon S3 and then use an S3 Lifecycle policy to transition the logs from the S3 Standard storage class to S3 Standard-Infrequent Access (S3 Standard-IA) after 90 days. During the initial 90-day window, the logs remain in S3 Standard for frequent access. After that, because the logs are only accessed intermittently, S3 Standard-IA provides a more cost-effective storage class.
Delivering VPC Flow Logs to Amazon S3 is a common approach for compliance requirements and cost efficiency. Amazon Kinesis does not offer an economical long-term storage solution for logs. Amazon CloudWatch Logs does include retention settings but lacks a cheaper storage tier for intermittent access. AWS CloudTrail is intended to record API calls in AWS, not to capture network traffic patterns.
In a real-world scenario, administrators often configure a short retention time in S3 Standard (for logs heavily accessed by security teams) and then configure a lifecycle rule that transitions objects to a cheaper storage class (like S3 Standard-IA) once access patterns diminish. This pattern reduces storage costs while still allowing occasional queries.
For example, imagine a DevOps team writing Athena queries to analyze log data for the first 90 days. Subsequently, the volume of queries diminishes, so the logs can move to S3 Standard-IA without sacrificing availability for occasional lookups.
Monitor your bucket storage costs and query patterns with AWS Cost Explorer to verify that your lifecycle and storage class settings offer the expected cost savings and data availability.
A development team has launched a new application that is hosted on Amazon EC2 instances inside a development VPC. A solutions architect needs to create a new VPC in the same account. The new VPC will be peered with the development VPC. The VPC CIDR block for the development VPC is 192.168.0.0/24.
The solutions architect needs to create a CIDR block for the new VPC. The CIDR block must be valid for a VPC peering connection to the development VPC.
What is the SMALLEST CIDR block that meets these requirements?
192.168.0.0/24
192.168.1.0/32
10.0.1.0/32
10.0.1.0/24
When creating a VPC for peering, the IP address ranges must not overlap. Since the development VPC has 192.168.0.0/24, it is not possible to use the same IP range for another peered VPC. Furthermore, AWS requires a CIDR block between /16 and /28 for a VPC. Both 192.168.1.0/32 and 10.0.1.0/32 are invalid because /32 is smaller than the minimum /28 subnet size. Therefore, the correct solution is 10.0.1.0/24, which provides a non-overlapping address range within the supported VPC CIDR limits.
In real-world scenarios, many companies choose a private IP space (for instance, 10.0.0.0/8, 172.16.0.0/12, or 192.168.0.0/16) large enough to scale subnets without overlap.
Always confirm that your chosen CIDR block is valid for VPC creation. Remember that AWS supports /16 through /28 for a VPC.





