AWS Certified AI Practitioner (AIF-C01)

- 557 exam-style questions
- Detailed explanations and references
- Simulation and custom modes
- Custom exam settings to drill down into specific topics
- 180-day access period
- Pass or money back guarantee
What is in the package
Stop guessing - start practicing. Thousands of students have used our prep materials to move from AI theory to real AWS skills.
The AWS Certified AI Practitioner (AIF-C01) is the first major certification focused on Generative AI in the cloud. At CertVista, we offer more than just questions - we give you a clear path to success. Our 500+ exam-style questions and detailed study guide help you understand services such as Amazon Bedrock, SageMaker, and Amazon Q.
Complete AIF-C01 domains coverage
Our practice exams fully align with the official AWS courseware and the Certified AI Practitioner exam objectives.
1. Fundamentals of AI and ML
We teach you the core principles of AI and ML, ensuring you can confidently differentiate between supervised, unsupervised, and reinforcement learning. Our focus is on helping you identify the right business use cases for machine learning and master the ML development lifecycle. We guide you through AWS’s managed AI services and train you on MLOps concepts and performance evaluation metrics, so you know exactly when a model is ready for production.
2. Fundamentals of Generative AI
We dive deep into the mechanics of Generative AI, teaching you the critical science behind tokens, embeddings, and the transformer architecture. We show you how to navigate the GenAI lifecycle—from understanding model capabilities to identifying its limitations. We prepare you to select the right AWS infrastructure and services, ensuring you can build generative applications while keeping cost-efficiency and technical scalability at the forefront.
3. Applications of Foundation Models
We show you exactly how to work with Foundation Models (FMs), focusing on high-impact techniques like Retrieval Augmented Generation (RAG) and model customization. We teach you the criteria for model selection and the art of advanced prompt engineering. We focus on practical implementation, ensuring you can evaluate model performance and translate technical AI capabilities into tangible business value.
4: Guidelines for Responsible AI
We prepare you to tackle the ethical side of AI with a focus on bias, fairness, and inclusivity. We teach you how to use AWS tools to build transparent, explainable AI models that meet modern regulatory requirements. We show you how to recognize legal risks and implement best practices for responsible development, ensuring your AI solutions are as ethical as they are innovative.
5. Security, Compliance, and Governance for AI Solutions
We train you to secure your AI infrastructure using the full suite of AWS security services. We focus on teaching you data governance strategies and the specific compliance standards required for AI implementations. We guide you through implementing privacy protocols and governance frameworks, ensuring your AI solutions are locked down, compliant, and ready for the enterprise.
We designed our exam engine to match the look, feel, and pressure of the AWS testing environment.
Our AIF-C01 question bank is more than just test prep; it is a full practice run. We challenge you with a variety of question types, such as multiple-choice, multiple-response, and new drag-and-drop matching scenarios, all based on real-world AI challenges.
By the time you take the actual exam, the interface and logic will feel familiar.
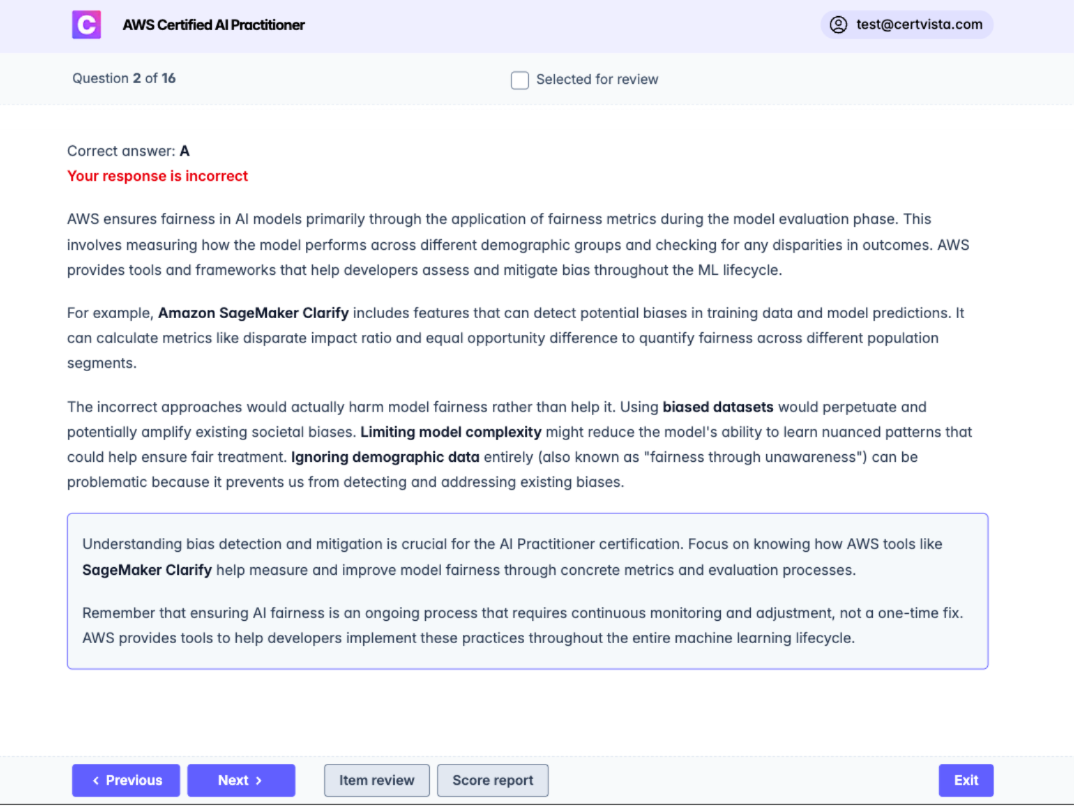
We believe that the best learning happens in the gaps. That’s why every question in the CertVista bank includes a comprehensive breakdown and direct references to official AWS documentation.
We don't just tell you which answer is right; we explain why the others are wrong. Our explanations clarify complex AI principles, debunk common misconceptions, and bridge the gap between abstract theory and practical AWS applications.
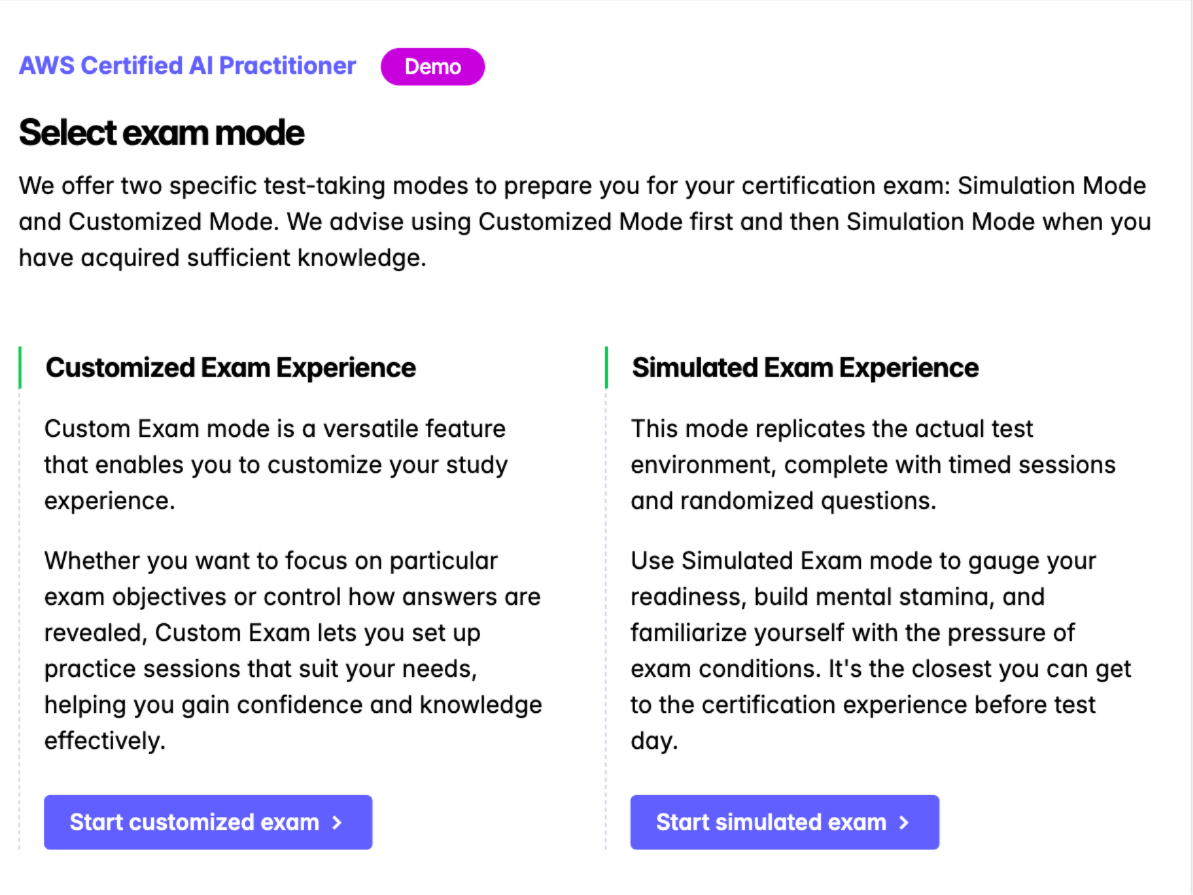
We give you full control over your study journey with two modes for different stages of your preparation. Use Custom Mode to focus on specific domains, which is great when you need to improve your knowledge in "Generative AI" or "Security."
When you are ready for the full experience, Simulation Mode recreates the 90-minute exam with real-time limits and question distribution, helping you build the mental stamina you need to cross the finish line.
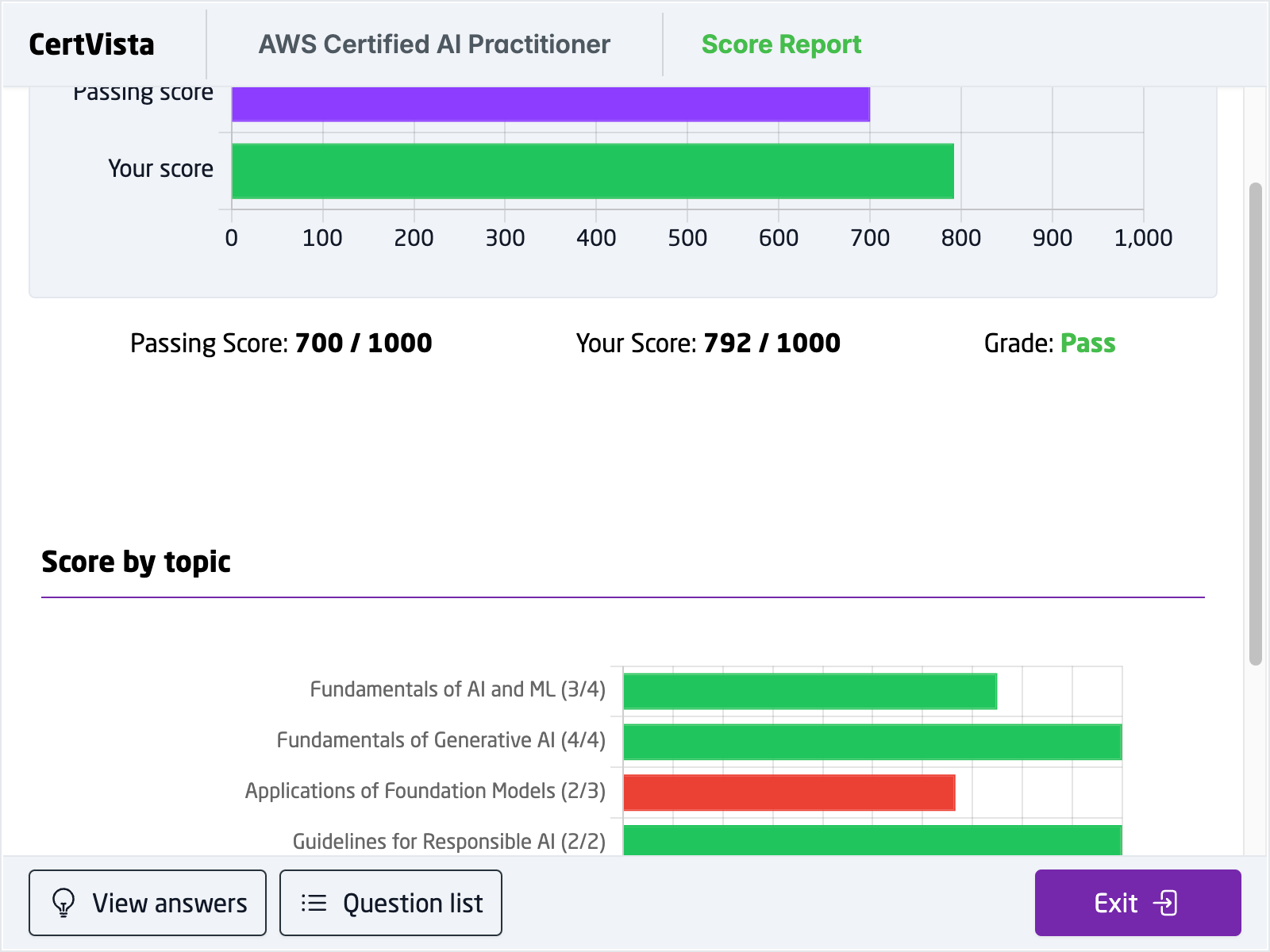
We provide the analytics you need to go from "feeling ready" to "being ready." The CertVista dashboard gives you clear, detailed insights into your performance across all five AIF-C01 domains.
We help you find your knowledge gaps, so you can stop spending time on what you already know and focus on the topics that will really improve your score.
What's in the AIF-C01 exam
Navigating the landscape of AI certifications can be daunting. As a leading provider of certification preparation materials, we have mentored thousands of professionals who struggled to identify the right starting point.
The AIF-C01 validates foundational knowledge of AI/ML and, crucially, Generative AI. Our guide and practice exams ensure you don't just memorize definitions, but understand how to apply these technologies to solve real-world business problems.
How AIF-C01 Compares to the Market
We often get asked how this certification stacks up against others. Here is our expert take:
| Certification | Provider | Focus area | Target audience | Our take |
|---|---|---|---|---|
| AWS AI Practitioner (AIF-C01) | AWS | Foundational AI, ML, and GenAI on AWS. | Beginners & Business Leaders | Top ROI. Focuses on the most dominant cloud AI ecosystem. |
| Azure AI Fundamentals (AI-900) | Microsoft | ML and AI implementation on Azure. | Beginners | Excellent for those in the Microsoft/OpenAI enterprise stack. |
| Google Cloud - Generative AI | Deep focus on Google's GenAI and Vertex AI. | Technical Leads | More niche; excellent for Google-specific AI tools. | |
| CompTIA AI Essentials | CompTIA | Vendor-neutral AI principles. | Business Generalists | Good for general theory, but lacks practical cloud application. |
Mastering AIF-C01 question types
The AIF-C01 exam is not a simple vocabulary test. AWS uses specific question formats to test your ability to apply AI concepts to real-world business scenarios. We have designed our simulator to mirror these exactly:
1. Multiple-Choice (single response)
The most common format. You are presented with a scenario and four options.
- The Challenge: Often, two answers seem correct. We teach you to look for keywords like "most cost-effective" or "least operational overhead" to identify the intended AWS best practice.
2. Multiple response
You must select two or more correct options from a list of five or more.
- The Pitfall: We warn our students - there is no partial credit. You must select all correct answers to earn the point. These questions typically test your knowledge of multi-step architectures or multiple features of a single service like Amazon Bedrock.
3. Matching && Drag-and-Drop
You will be asked to match items from two columns - for example, matching specific AWS services (Rekognition, Polly, Lex) to their correct functional descriptions.
- Our Approach: Our practice bank includes matching scenarios that help you build the mental associations required to categorize services instantly.
4. Ordering (sequencing)
You must arrange a list of steps in the correct order.
- Common Examples: The steps in the Machine Learning Lifecycle or the workflow for implementing Retrieval-Augmented Generation (RAG). We provide detailed diagrams in our study guide to help you visualize these sequences.
The following video presents an example of an AIF-C01 ordering question:
Watch out: common tricks & pitfalls
Through our years of training, we’ve identified the specific traps where even experienced cloud professionals get tripped up. Our materials are designed to help you avoid these:
- The "Deterministic" Trap: AWS often includes a distractor where an AI model provides a "guaranteed, exact output." We remind our students: ML models are probabilistic. If a scenario requires 100% exact math (like accounting), ML is usually the wrong answer.
- Hyperparameter Confusion: The exam loves to swap Temperature, Top P, and Top K. Our guide provides the "Instructor’s Mnemonics" to keep these straight (e.g., higher temperature = more "creative" heat).
- Prompting vs. Fine-Tuning: A classic pitfall is choosing "Fine-Tuning" for a task that only requires "Prompt Engineering." We help you identify the most cost-effective solution for every scenario.
Key details of the AIF-C01 exam
Here is a summary of the essential information as of early 2026.
| Exam Detail | Description |
|---|---|
| Exam Name | AWS Certified AI Practitioner |
| Exam Code | AIF-C01 |
| Number of Questions | 65 questions (50 scored, 15 unscored) |
| Time Allotted | 90 minutes |
| Passing Score | 700 / 1,000 |
| Exam Cost | $100 USD (plus applicable taxes) |
| Question Formats | Multiple choice, multiple response, ordering, and matching |
| Delivery Method | Pearson VUE testing center or online proctored exam |
How we recommend you prepare
- Read Our Study Guide: Build a solid conceptual foundation across all 5 domains. We cover every service from SageMaker to Bedrock.
- Gain Foundational Knowledge: If you are brand new to the cloud, start with the AWS Cloud Practitioner Essentials.
- Get Hands-On: Use the AWS Free Tier to experiment with Amazon Bedrock and Amazon Q. Seeing the console makes the theory "stick."
- Practice with Realistic Scenarios: Use our question bank to build stamina. We recommend aiming for a consistent 85% score on our simulations before booking your real exam.
Don't leave your certification to chance. Join the thousands of professionals who have used CertVista to fast-track their AI careers.
By Beana Ammanath, a Certified AI Strategist with over a decade of experience implementing cloud-based machine learning solutions.
Sample AIF-C01 questions
Get a taste of the AWS Certified AI Practitioner exam with our carefully curated sample questions below. These questions mirror the actual AIF-C01 exam's style, complexity, and subject matter, giving you a realistic preview of what to expect. Each question comes with comprehensive explanations, relevant documentation references, and valuable test-taking strategies from our expert instructors.
While these sample questions provide excellent study material, we encourage you to try our free demo for the complete AIF-C01 exam preparation experience. The demo features our state-of-the-art test engine that simulates the real exam environment, helping you build confidence and familiarity with the exam format. You'll experience timed testing, question marking, and review capabilities – just like the actual certification exam.
A company needs to implement an AI solution that can convert natural language input into SQL queries for their large-scale database analysis. The solution should be user-friendly for employees with limited technical expertise.
Which AI model would be most appropriate for this use case?
Generative pre-trained transformers (GPT)
Residual neural network
Support vector machine
WaveNet
Generative pre-trained transformers (GPT) is the most suitable solution for this scenario. GPT models excel at understanding and processing natural language input, making them ideal for converting plain English requests into structured SQL queries. They can understand context and intent behind user queries, which is crucial for employees with minimal technical experience.
The practical effectiveness of GPT for this use case has been demonstrated by major companies like Uber, which have successfully implemented GPT-based solutions for SQL query generation in enterprise environments. GPT models have consistently shown superior performance in text-to-SQL tasks compared to other AI models. Furthermore, GPT can handle complex database schemas and generate accurate SQL queries for large-scale data analysis. The model can be fine-tuned to understand specific business contexts and database structures, making it highly adaptable to different enterprise needs.
The other options are not suitable for this specific use case. Residual Neural Network, while powerful for image processing and deep learning tasks, is not specifically designed for natural language understanding and SQL generation. Support Vector Machine is a traditional machine learning algorithm better suited for classification and regression tasks, not complex language processing and query generation. WaveNet is a deep neural network primarily designed for audio generation and speech synthesis, making it inappropriate for text-to-SQL conversion.
When evaluating AI solutions for natural language processing tasks, particularly those involving text transformation or generation, GPT models are often the strongest candidates due to their advanced language understanding capabilities.
When building a prediction model, what's the relationship between underfitting/overfitting and bias/variance?
Underfit models experience high bias. Overfit models experience high variance.
Underfit models experience high bias. Overfit models experience low variance.
Underfit models experience low bias. Overfit models experience low variance.
Underfit models experience low bias. Overfit models experience high variance.
Understanding the relationship between underfitting/overfitting and bias/variance is fundamental in machine learning model development.
Bias refers to the error introduced by approximating a real-world problem, which may be complex, by a too-simple model. High bias means the model makes strong assumptions about the data, leading it to miss relevant relations between features and target outputs. This results in underfitting, where the model performs poorly even on the training data because it cannot capture the underlying trend.
Variance refers to the amount by which the model's learned function would change if it were trained on a different training dataset. High variance means the model is highly sensitive to the specific training data, learning noise and random fluctuations. This leads to overfitting, where the model performs exceptionally well on the training data but fails to generalize to new, unseen data.
Therefore, an underfit model (too simple) suffers from high bias because its fundamental assumptions prevent it from capturing the data's complexity. An overfit model (too complex) suffers from high variance because it learns the training data too specifically, including noise, making it perform poorly on different datasets.
The goal in model building is often described as finding a balance in the bias-variance tradeoff – creating a model that is complex enough to capture the underlying patterns (low bias) but not so complex that it learns the noise (low variance).
Remember these core associations: Underfitting = High Bias (model too simple, makes wrong assumptions) and Overfitting = High Variance (model too complex, learns noise, doesn't generalize). Visualize a simple linear model trying to fit a complex curve (high bias/underfitting) versus a high-degree polynomial wiggling to hit every single training point (high variance/overfitting).
Which SageMaker service helps split data into training, testing, and validation sets?
Amazon SageMaker Feature Store
Amazon SageMaker Clarify
Amazon SageMaker Ground Truth
Amazon SageMaker Data Wrangler
Preparing data for machine learning often involves splitting the dataset into subsets for training, validation, and testing. This ensures that the model is trained on one portion of the data, tuned on another, and finally evaluated on unseen data.
Amazon SageMaker Data Wrangler is designed to simplify the process of data preparation for ML. It provides a visual interface and a comprehensive set of built-in data transformations to help data scientists and engineers aggregate, prepare, and transform data. Among its capabilities, Data Wrangler allows users to apply various transformations, including those needed to split a dataset into training, validation, and testing sets based on specified criteria or proportions.
Amazon SageMaker Feature Store is a repository for storing, retrieving, and managing ML features, but it doesn't perform the splitting operation itself.
Amazon SageMaker Clarify focuses on detecting potential bias in data and explaining model predictions, not on splitting datasets for training.
Amazon SageMaker Ground Truth is a data labeling service used to create labeled datasets, which are often the input for the preparation phase, but it doesn't perform the train/test/validation split.
Think of Data Wrangler as the primary SageMaker tool for preparing raw data before training. This includes cleaning, transforming, and structuring data, which often involves splitting it. Associate Feature Store with managing features, Clarify with bias and explainability, and Ground Truth with labeling.
A company wants to build an interactive application for children that generates new stories based on classic stories. The company wants to use Amazon Bedrock and needs to ensure that the results and topics are appropriate for children.
Which AWS service or feature will meet these requirements?
Amazon Rekognition
Amazon Bedrock playgrounds
Guardrails for Amazon Bedrock
Agents for Amazon Bedrock
Guardrails for Amazon Bedrock provide a mechanism to implement safeguards for generative AI applications. They allow users to define specific policies to control the interaction between users and foundation models (FMs). Key features relevant to this scenario include:
- Denied Topics: Administrators can define topics that the application should not engage with. For a children's application, this could include sensitive or adult themes.
- Content Filters: Guardrails offer configurable filters to detect and block harmful content across categories like hate speech, insults, sexual content, and violence, based on specified thresholds.
- Word Filters: Specific words can be blocked.
- PII Redaction: Personally Identifiable Information can be filtered out.
By configuring Guardrails, the company can enforce content policies consistently across the different FMs available through Bedrock, ensuring the generated stories align with the requirement of being appropriate for children.
Amazon Rekognition is an image and video analysis service and is not used for moderating text generated by Bedrock models.
Amazon Bedrock playgrounds are environments for experimenting with models, not for implementing runtime safety controls in a deployed application.
Agents for Amazon Bedrock enable the creation of applications that can perform tasks using APIs, but they do not inherently provide the content filtering capability required; Guardrails are used to provide safety for agents and direct model invocations.
Therefore, Guardrails for Amazon Bedrock is the appropriate feature to meet the requirement for content safety and appropriateness.
When questions involve ensuring safety, appropriateness, or filtering harmful content in generative AI applications built on AWS, immediately think of Guardrails for Amazon Bedrock. It's the purpose-built feature for implementing these types of policies.
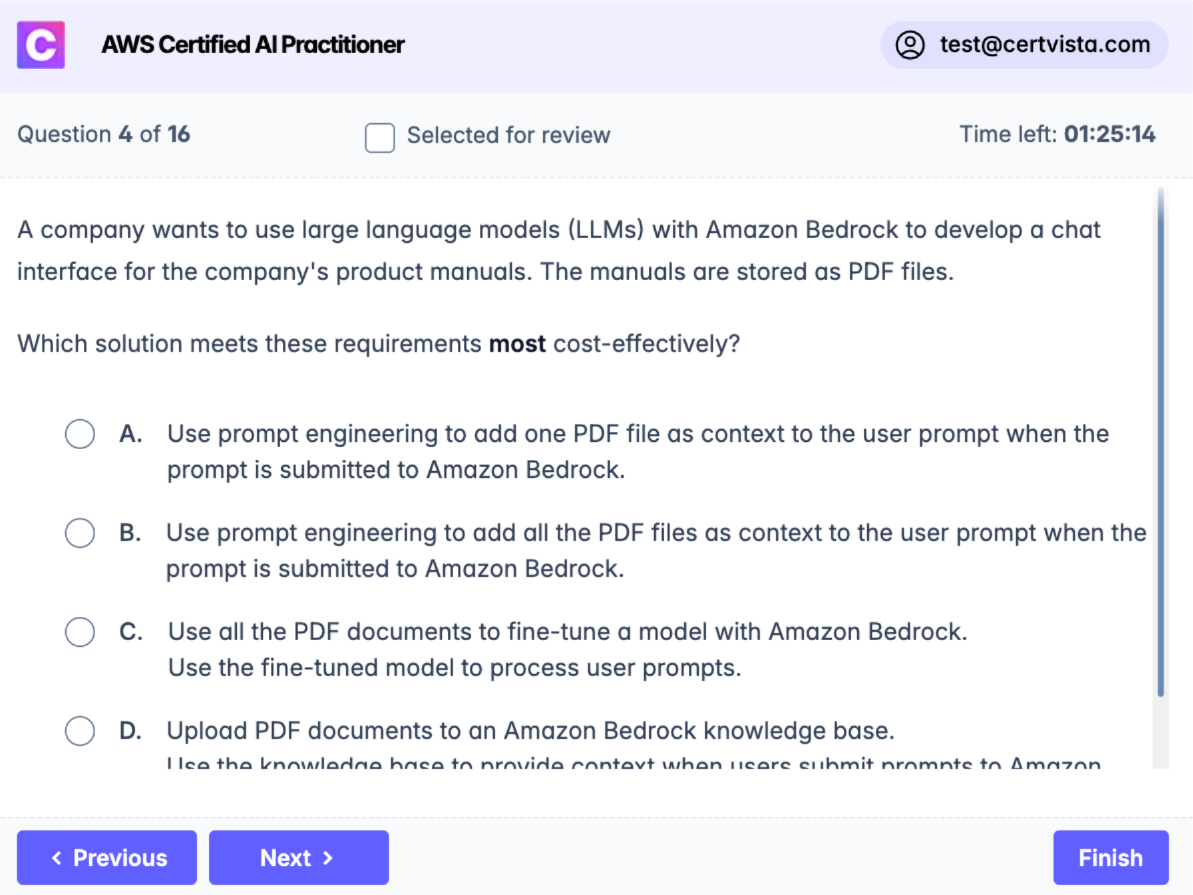
A company wants to use large language models (LLMs) with Amazon Bedrock to develop a chat interface for the company's product manuals. The manuals are stored as PDF files.
Which solution meets these requirements most cost-effectively?
Use prompt engineering to add one PDF file as context to the user prompt when the prompt is submitted to Amazon Bedrock.
Use prompt engineering to add all the PDF files as context to the user prompt when the prompt is submitted to Amazon Bedrock.
Use all the PDF documents to fine-tune a model with Amazon Bedrock. Use the fine-tuned model to process user prompts.
Upload PDF documents to an Amazon Bedrock knowledge base. Use the knowledge base to provide context when users submit prompts to Amazon Bedrock.
Using Amazon Bedrock knowledge base is the most cost-effective solution for this use case. Knowledge bases implement a managed Retrieval Augmented Generation (RAG) architecture that efficiently retrieves relevant information from the uploaded documents when needed. This approach optimizes both performance and cost by only retrieving and using relevant portions of the documents for each query.
The other approaches have significant drawbacks:
Adding a single PDF file as context through prompt engineering would limit the chatbot's ability to access information from other manuals, requiring multiple queries and increasing costs. This would also provide incomplete responses if the information spans multiple manuals.
Including all PDF files as context in every prompt would be highly inefficient and expensive. This approach would unnecessarily increase token usage and processing costs for each query, even when only a small portion of the documentation is relevant.
Fine-tuning the model with all PDF documents would be the most expensive option. It requires significant computational resources and typically takes longer compared to other approaches. Additionally, updating the model with new or modified documentation would require repeated fine-tuning, increasing costs further.
When evaluating solutions involving document processing with LLMs, consider both the immediate implementation costs and long-term operational efficiency. Knowledge bases often provide the best balance between functionality and cost-effectiveness for document-heavy applications.
A company wants to use a large language model (LLM) to develop a conversational agent. The company needs to prevent the LLM from being manipulated with common prompt engineering techniques to perform undesirable actions or expose sensitive information.
Which action will reduce these risks?
Create a prompt template that teaches the LLM to detect attack patterns.
Increase the temperature parameter on invocation requests to the LLM.
Avoid using LLMs that are not listed in Amazon SageMaker.
Decrease the number of input tokens on invocations of the LLM.
Creating a prompt template that teaches the LLM to detect attack patterns is the correct approach. This method provides a robust defense mechanism against prompt injection attacks. Well-designed prompt templates with security guardrails can detect and prevent various attack patterns, including prompted persona switches, attempts to extract prompt templates, and instructions to ignore security controls.
The template can incorporate specific guardrails that validate input, sanitize prompts, and establish secure communication parameters. This approach is particularly effective because it addresses security at the foundational level of the LLM's interaction with users, creating a first line of defense against malicious inputs.
As for the incorrect options, increasing the temperature parameter would actually make the model's outputs less predictable and potentially more vulnerable to manipulation. Limiting LLM selection to those listed in SageMaker doesn't address the core security concerns, as security depends on implementation rather than the model source. Reducing input tokens is an ineffective approach since sophisticated attacks can be executed with minimal tokens while this restriction would unnecessarily limit the model's legitimate functionality.
When evaluating LLM security measures, focus on solutions that directly address the specific security concern at the interaction level rather than general model parameters or arbitrary restrictions.
Your company wants to use machine learning to better understand customer and sales patterns using unlabeled data.
Which two methods would help you discover patterns automatically? (Select two.)
Clustering
Dimensionality reduction
Sentiment analysis
Neural network
Decision tree
To understand customer and sales patterns using unlabeled data, your company should employ unsupervised learning methods that can automatically discover inherent structures and relationships within the data.
Clustering is an unsupervised learning technique ideal for this scenario. It works by grouping data points—in this case, customers or sales transactions—into clusters based on their similarities. For instance, clustering could reveal distinct customer segments based on purchasing behavior (e.g., high-value customers, infrequent buyers, customers who prefer specific product categories) or identify common patterns in sales data (e.g., product bundles frequently bought together). These discovered clusters represent patterns that were not explicitly defined beforehand.
Dimensionality reduction is another valuable unsupervised learning method for discovering patterns. It aims to reduce the number of features (variables) in a dataset while retaining essential information. By transforming high-dimensional data (e.g., customer data with many attributes) into a lower-dimensional space, dimensionality reduction can help uncover underlying patterns and relationships that might be obscured in the original data. For example, it could reveal the most influential factors driving customer behavior or simplify complex sales data to make trends more apparent.
Sentiment analysis, while useful for understanding customer opinions, is typically a supervised learning task that requires labeled text data (e.g., reviews labeled as positive, negative, or neutral) to train a model.
A neural network is a type of model architecture that can be used for various tasks, including supervised and unsupervised learning, but it's not a specific method for pattern discovery in unlabeled data without further context (like an autoencoder for dimensionality reduction).
A decision tree is a supervised learning algorithm used for classification or regression tasks, which requires labeled data to learn the decision rules.
Remember that when dealing with unlabeled data and the goal is to discover hidden patterns or structures automatically, unsupervised learning techniques like clustering and dimensionality reduction are the primary methods to consider.
References:
- What is Unsupervised Learning? - AWS
- Clustering data - Amazon SageMaker
- Dimensionality Reduction - Amazon SageMaker (Context for PCA, a common dimensionality reduction technique)
A media company is deploying machine learning models with Amazon SageMaker to provide personalized content recommendations. They have intermittent workloads and don't want to manage the underlying infrastructure. They are looking for a deployment model that offers cost savings through cold starts.
Which deployment model should they choose?
Asynchronous Inference
Serverless Inference
Real-time hosting services
Batch Transform
For a media company with intermittent workloads that wants to provide personalized content recommendations using Amazon SageMaker, and is looking for a deployment model that offers cost savings through mechanisms like cold starts without requiring infrastructure management, Serverless Inference is the most suitable choice.
Amazon SageMaker Serverless Inference is designed specifically for workloads that are intermittent or have infrequent traffic patterns. It automatically provisions, scales, and turns off compute resources based on the volume of inference requests. When there are no requests, it can scale down to zero, meaning the company doesn't pay for idle compute capacity. When a new request comes in after a period of inactivity, a 'cold start' might occur as resources are provisioned, but this is the trade-off for significant cost savings during idle times. Because it's serverless, AWS manages the underlying infrastructure, so the company's development team doesn't need to worry about provisioning or managing servers.
Asynchronous Inference is suitable for large payloads and long processing times, where clients don't need an immediate response. While it can handle intermittent traffic, its cost model and primary design aren't focused on the 'scale to zero' and cold-start-for-cost-saving dynamic in the same way Serverless Inference is. Real-time hosting services (persistent SageMaker endpoints) involve provisioned instances that run continuously, incurring costs even during idle periods, which is not ideal for highly intermittent workloads where cost optimization is key. Batch Transform is used for offline processing of large datasets and is not suitable for providing real-time or near real-time personalized content recommendations.
For the AIF-C01 exam, remember that 'serverless' in the context of SageMaker Inference implies automatic scaling, pay-per-use (even scaling to zero), and no infrastructure management. The mention of 'cold starts' as a factor in cost savings strongly points towards a serverless paradigm where resources are spun up on demand after being idle.
A company is using a large language model (LLM) on Amazon Bedrock to build a chatbot. The chatbot processes customer support requests. To resolve a request, the customer and the chatbot must interact a few times.
Which solution gives the LLM the ability to use content from previous customer messages?
Turn on model invocation logging to collect messages.
Add messages to the model prompt.
Use Provisioned Throughput for the LLM.
Use Amazon Personalize to save conversation history.
A chatbot built with a Large Language Model (LLM) to effectively handle multi-turn customer support requests needs to have a memory of the preceding conversation. The standard method to achieve this is to add previous messages to the model prompt for each new turn of the conversation.
When a customer sends a new message, the application managing the chatbot should construct a prompt for the LLM that includes the latest customer message and the relevant history of the conversation (e.g., the last few turns of both customer and chatbot messages). This contextual information allows the LLM to understand the ongoing dialogue, refer to earlier points, and provide coherent and relevant responses to the entire interaction, rather than just the most recent utterance. This technique is fundamental to building stateful conversational AI.
Turning on model invocation logging is useful for auditing, debugging, or collecting data for later analysis, but it does not provide real-time conversational context to the LLM during an interaction. Using Provisioned Throughput for the LLM ensures dedicated inference capacity and consistent performance, which is important for production applications, but it doesn't address the LLM's need for conversational history. Amazon Personalize is a service for creating personalized recommendations for users based on their past behavior and preferences; while it deals with user history, it's not designed for managing the turn-by-turn context of an LLM-powered chatbot conversation.
Understand that LLMs are generally stateless by default for each API call. To create a conversational experience, the application layer must manage and provide the conversation history as part of the prompt to the LLM for each new interaction.
References:
- Prompt engineering guidelines - Amazon Bedrock (Discusses building effective prompts, which is key for conversational context)
- Building chatbots on AWS: A comprehensive guide - AWS Blogs (Provides general context on chatbot architecture)
A company built an AI-powered resume screening system. The company used a large dataset to train the model. The dataset contained resumes that were not representative of all demographics.
Which core dimension of responsible AI does this scenario present?
Explainability
Privacy and security
Transparency
Fairness
The core dimension of responsible AI presented in this scenario is Fairness. The situation describes a training dataset that is not representative of all demographics, which can lead to biased or unfair outcomes when the AI model is used in real-world screening scenarios. Fairness in AI ensures that outcomes are impartial and unbiased, providing an equal opportunity for all individuals regardless of their demographic background.
The concept of Explainability focuses on the ability to understand and interpret the AI model's decisions, which is not directly addressed in this scenario. Privacy and security are concerned with protecting personal data from unauthorized access, which is also not relevant here. Transparency involves the openness and clarity with which AI processes and decisions are communicated, which is a related but distinct aspect from fairness.
When assessing scenarios related to AI model training and data usage, pay attention to whether the data is representative and unbiased to ensure fairness. The presence of biased data is a key indicator of fairness issues.
Related exams






Frequently Asked Questions
Yes, absolutely. The AIF-C01 exam is deceptively broad, requiring you to quickly differentiate between overlapping AI and ML concepts, AWS AI services, and responsible AI principles across a wide range of real-world scenarios—a common stumbling block for first-time candidates. From our experience, CertVista's practice exams are the most effective tool to master this skill. Our realistic test engine simulates the actual exam environment, moving you beyond simple memorization to train the critical ability of applying AI knowledge correctly under pressure, which is the key to passing the AWS Certified AI Practitioner exam.
Based on performance data from thousands of successful users, the clear benchmark for success is consistently scoring 85% or higher across multiple CertVista practice exams. Achieving this score indicates you have a firm grasp of AI and machine learning fundamentals, AWS AI/ML services, and responsible AI practices, and can apply them effectively under timed conditions. It proves you are truly ready and strongly correlates with a first-time pass on the official AIF-C01 exam.
CertVista provides a professional preparation tool where free quizzes fall short. The key differences are our realism, with questions that meticulously mirror the AIF-C01's scenario-based format, and our in-depth explanations for every answer choice—correct and incorrect—which transforms practice into a powerful learning tool. We also guarantee 100% coverage of all official AIF-C01 exam domains, including generative AI concepts, foundation models, and AWS AI services, and provide performance analytics to pinpoint your weak areas, ensuring your study time is as efficient as possible.
The single biggest mistake we see is candidates confusing the specific use cases for similar AWS AI and ML services (e.g., Amazon Comprehend vs. Amazon Rekognition, or Amazon Bedrock vs. Amazon SageMaker). CertVista's practice exams are specifically engineered to solve this problem. We immerse you in realistic, scenario-based questions that force you to make these critical distinctions repeatedly until the unique purpose of each service becomes second nature, eliminating the confusion that causes many AIF-C01 candidates to fail.
The AIF-C01 exam primarily uses multiple-choice and the more challenging multiple-response formats, both of which are extensively covered in our CertVista test engine. While other formats may appear, our preparation methodology inherently prepares you for them. By focusing on the relationships between AI concepts, AWS service capabilities, and responsible AI best practices, our scenario-based questions and detailed explanations build a core competency that allows you to analyze and correctly answer any question format AWS might present on the AI Practitioner exam.